我先尝尝😋
作为一个从没有听说过vLLM的人来说,了解一个新东西最好的方式就是打开它的文档。
点击https://docs.vllm.ai/,映入眼帘的是:

你注意到了这句话:
vLLM is a fast and easy-to-use library for LLM inference and serving.
来自谷歌翻译:vLLM 是一个快速且易于使用的 LLM 推理和服务库。
下面我们从这句话入手!
到底什么是LLM?
全称Large Language Model,也就是大语言模型
诸如Deepseek、GPT、Claude这种,简单来说就是“能看懂人类语言、还能像人类一样写作和对话”的 AI 模型。
到底什么是推理?
简单来说就是用训练好的模型做“预测”或“生成”。
例如:
你打开Deepseek的官网,输入:我晚上吃什么好?
1.大模型睁眼一看
它看到你说“我晚上吃什么好?”,立刻判断这是一个在询问建议的问题。
2.开始在脑子里翻找
它读过成千上万次人类关于晚餐的话题,比如:“要不要吃点好的?”、“可以做个炒饭”、“点外卖也不错”。
3.思考上下文
虽然你没有明确说你是自己做、外出吃还是点外卖,它会尝试给出一个通用又贴心的建议。
4.组织语言
它挑选出一个符合语境、听起来自然的回答,比如“可以吃点清淡的,比如炒青菜加鸡蛋汤“。
经过一会儿的头脑风暴,你就得到了回答。上面这个头脑风暴的过程就可以被称为推理。
还有个v呢?
在官方文档中并没有找到关于v的解释,不过我们可以从github中发现线索:
代表从操作系统中虚拟内存的分页管理技术受到启发
总结
总而言之,vLLM是一个加速大模型推理过程的工具。
我再尝尝😋
推理过程在干嘛?
一个常规的LLM推理过程通常分为两个阶段prefill和decode,通常会使用KV cache技术加速推理。
(又听不懂了对吧,接下来听我娓娓道来..)
- prefill阶段(存放输入)
- 把用户输入的整段文本(prompt)一次性输入到模型里,让模型从头到尾对这段文本进行一次完整的计算,计算出它对每个词(token)的理解和关系。将计算得到的东西(一些KV值)存放在KV cache里。
- decode阶段(生成输出)
- 根据prefill填充的内容,一个token一个token的生成输出文本(response)
例如:你输入I like eating,想让模型续写后面的内容。将I like eating存下来的阶段
就是prefill,续写后生成I like eating pizza and rice的阶段就是decode
为什么KV cache能加速推理?
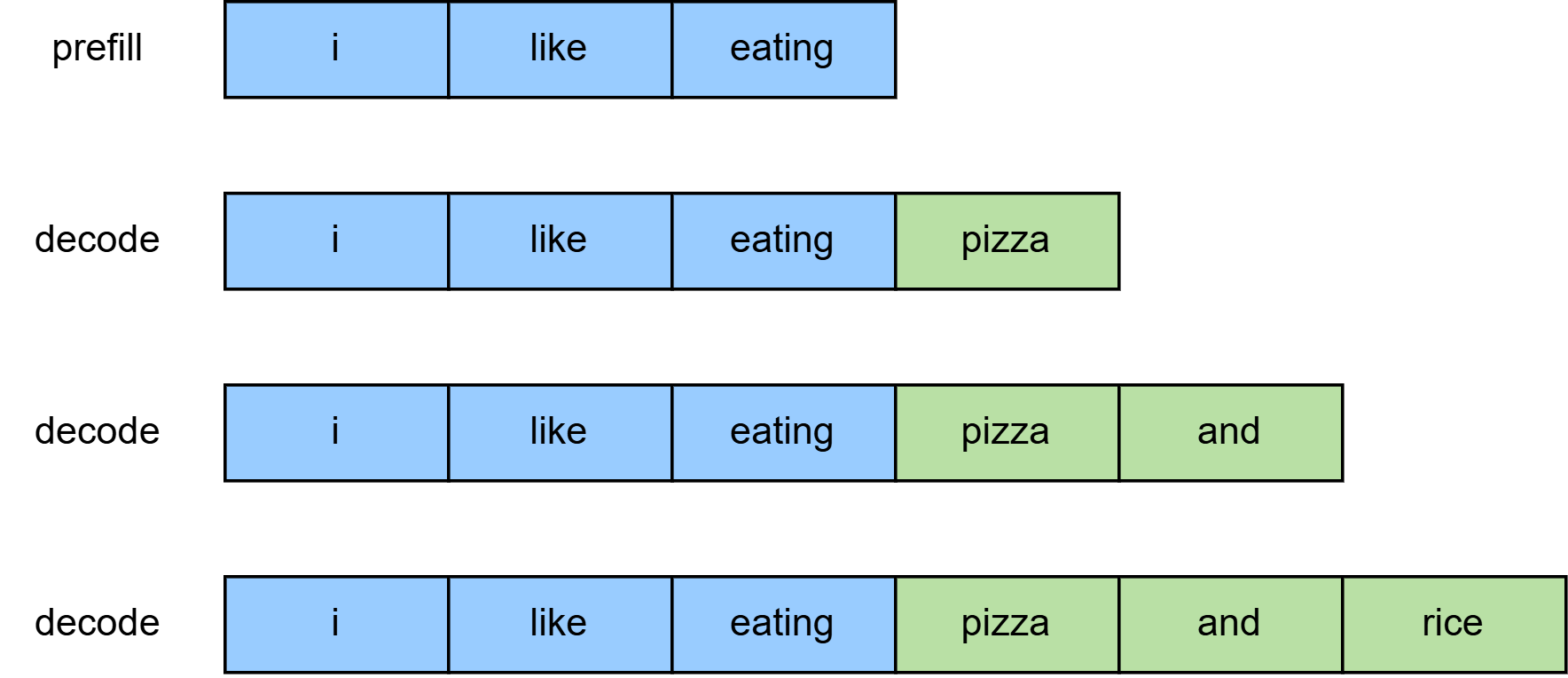
如上图所示,Decode 阶段是模型一个token接一个token地生成 response。
每生成一个新token,模型都需要结合前面所有 token来计算注意力(attention)。
如果每次都重新计算前面所有 token 的值,会造成大量重复计算,效率低下。
为了避免这种重复,我们把前面 token 的中间结果(Key 和 Value)保存在 KV cache 中,
下一次直接复用这些缓存,从而大幅加快推理速度。
简单来说:
- 每生成一个词,模型都得回顾之前写的所有词
- 缓存(KV Cache)让它不用每次都重头想起之前的内容,直接拿来用(避免重复计算)
两个阶段的差异性
- 在prefill阶段,整个prompt是已知的完整序列,模型可以同时处理所有的token(并行计算)
- 在decode阶段,模型是一个一个地生成token,每生成一个新token,都要依赖前面生成地结果,所以只能串行计算。故这个阶段耗时更大。
为什么需要vLLM?
从上述过程中,我们可以发现使用KV cache做推理时的特点:
- 随着prompt数量变多和序列变长,KV cache也变大,对GPU显存造成压力
- 由于decode阶段输出的序列长度无法预先知道,所以很难提前为KV cache定制存储空间
因此,如何优化KV cache,节省显存,提高推理吞吐量,就成了LLM推理框架需要重点解决的问题!